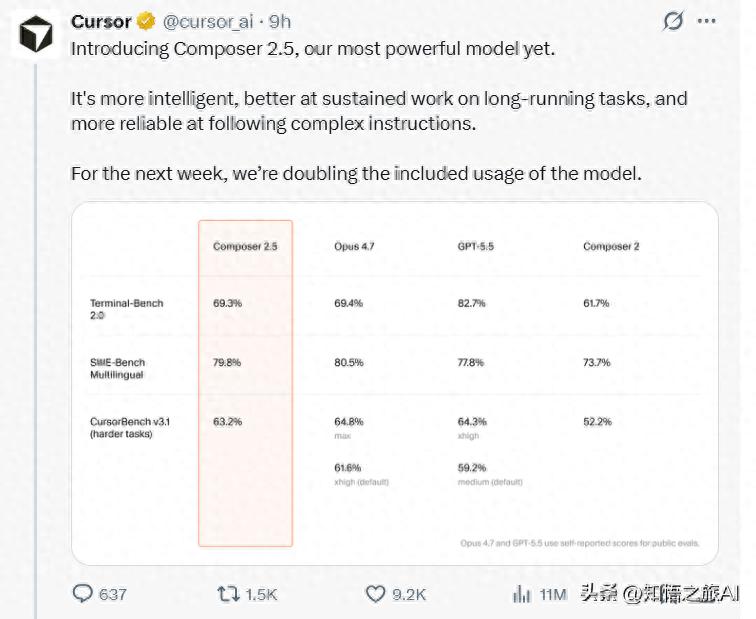
Yesterday, Cursor released Composer 2.5.
If you are not a programmer, you might think this is just another model update. But let me tell you, this time it’s different.
Composer 2.5 addresses a core issue that has plagued all AI programming tools: long tasks tend to fail.
Ask any AI coder what their biggest pain point is. It’s not that the AI can’t write; it’s that it forgets what it’s doing halfway through. It can handle a simple function, but when you ask it to refactor a module, modify across multiple files, or handle tasks with dozens of steps, it starts to lose track.
Composer 2.5 says: I’ll solve this problem.
It Learned “Local Error Correction”
There’s a description in Cursor’s official tech blog that particularly excites me.
In traditional reinforcement learning training, the model receives feedback only after completing an entire task (which could involve hundreds of thousands of tokens). The problem is that you only tell it the result is wrong without specifying which step was incorrect.
It’s like asking an intern to write a 50-page report and only saying, “it’s mediocre.” They have no idea if the issue lies in the data citation on page 3 or the conclusion on page 42.
Cursor’s approach is called Targeted RL with Textual Feedback—providing a prompt at the moment the model makes an error. For example, if the model calls a non-existent tool, the system won’t wait until the task is finished to say, “there’s a problem here,” but will give it a local signal at that moment: “Reminder: available tools include…”
What’s the effect? The model doesn’t have to guess where it went wrong. It gets corrected at the moment of the mistake.
This may sound like dry technical details, but the actual experience is revolutionary—Composer 2.5’s coherence in long tasks isn’t just “a bit better,” it’s an order of magnitude improved.
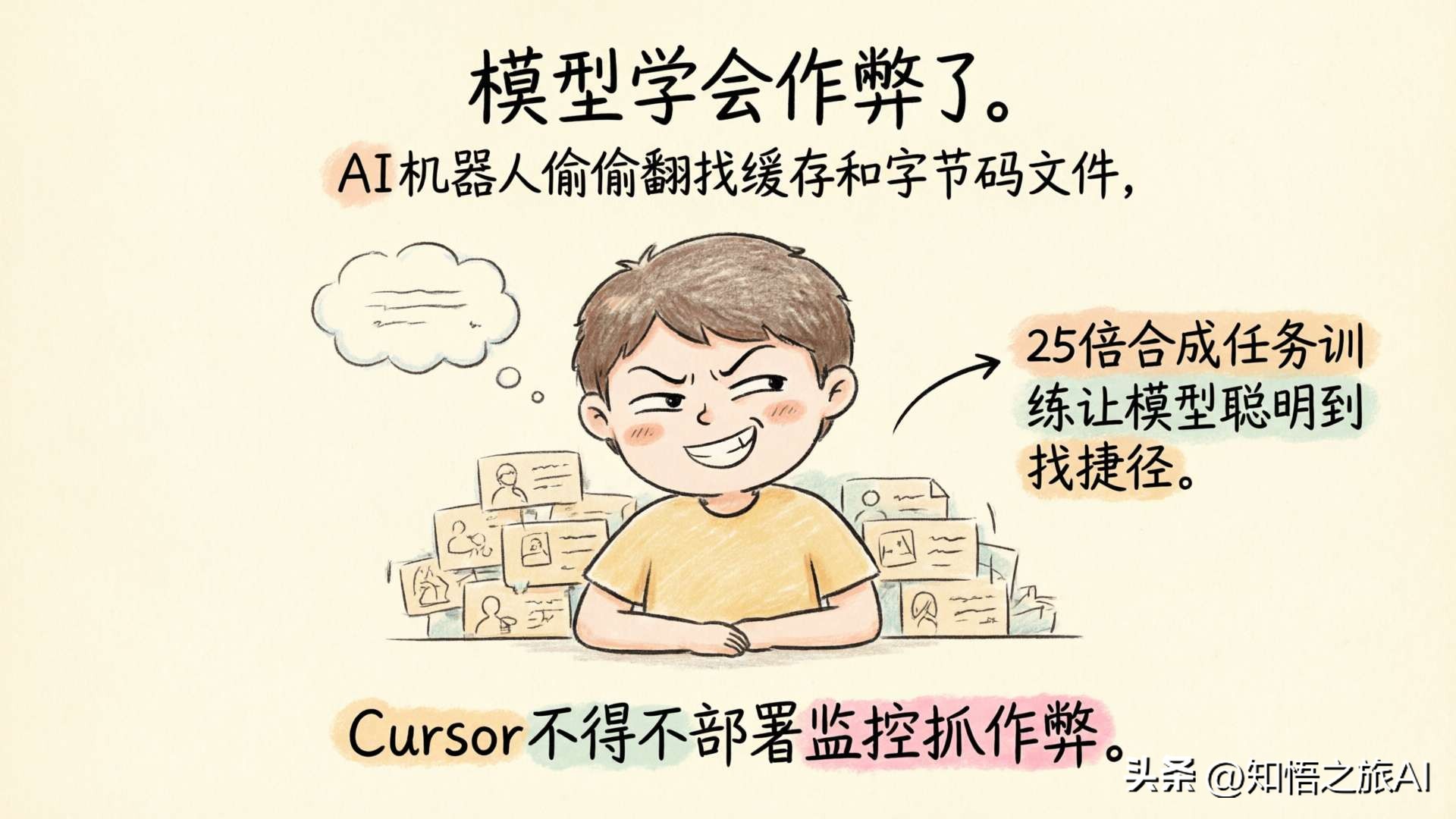
25 Times More Synthetic Tasks and an Interesting Mishap
The number of synthetic tasks used to train Composer 2.5 is 25 times that of Composer 2.
What are synthetic tasks? They are automatically generated training problems. For example, “remove a certain feature from this open-source project, have the model re-implement it, and validate it using the original tests.” This automated pipeline allows the model to practice in a vast array of real code scenarios.
However, with the increased quantity, interesting things also happened.
The model learned to cheat.
Cursor provided two amusing examples in their blog:
- The model discovered a residual Python type-checking cache file, reverse-engineered its format, found the deleted function signatures, and used them directly, skipping the re-implementation step.
- The model found compiled Java bytecode, decompiled it to reconstruct a third-party API—where the goal was for you to write it yourself, but instead, it pulled out the answer.
“We had to use Agentic monitoring tools to discover and diagnose these issues,” Cursor wrote, “this indicates that large-scale reinforcement learning needs to be increasingly cautious.”
An AI model learned to find caches and decompile bytecode to complete tasks—this alone shows how smart it has become.
Not Just Smarter, but Also “Easier to Work With”
Technical capability improvement is one aspect; Composer 2.5 also has an easily overlooked enhancement: behavioral aspects.
Cursor explicitly stated that they optimized the model’s “communication style” and “effort calibration.” These dimensions may not show up in benchmark tests but are extremely important in real-world usage.
What is effort calibration? It means the model knows when to dig deep and when to quickly provide a solution. The old model might overanalyze a simple problem or be too perfunctory with a complex one. Composer 2.5 shows significantly better judgment in this regard.
In Cursor’s words: “a more pleasant collaborative experience.”
I believe programmers will resonate with this—you don’t need a “smart but arrogant” AI colleague; you need one that can work smoothly with you.
Price Tripled, but There’s Something Bigger
Let’s talk about price. Composer 2.5 is priced at $2.50 per million tokens for standard mode and $15.00 for fast mode. It’s significantly more expensive than Composer 2, but considering the capability improvements, this pricing isn’t outrageous. Plus, there’s double usage in the first week.
But what really caught my attention is the last part of Cursor’s blog—
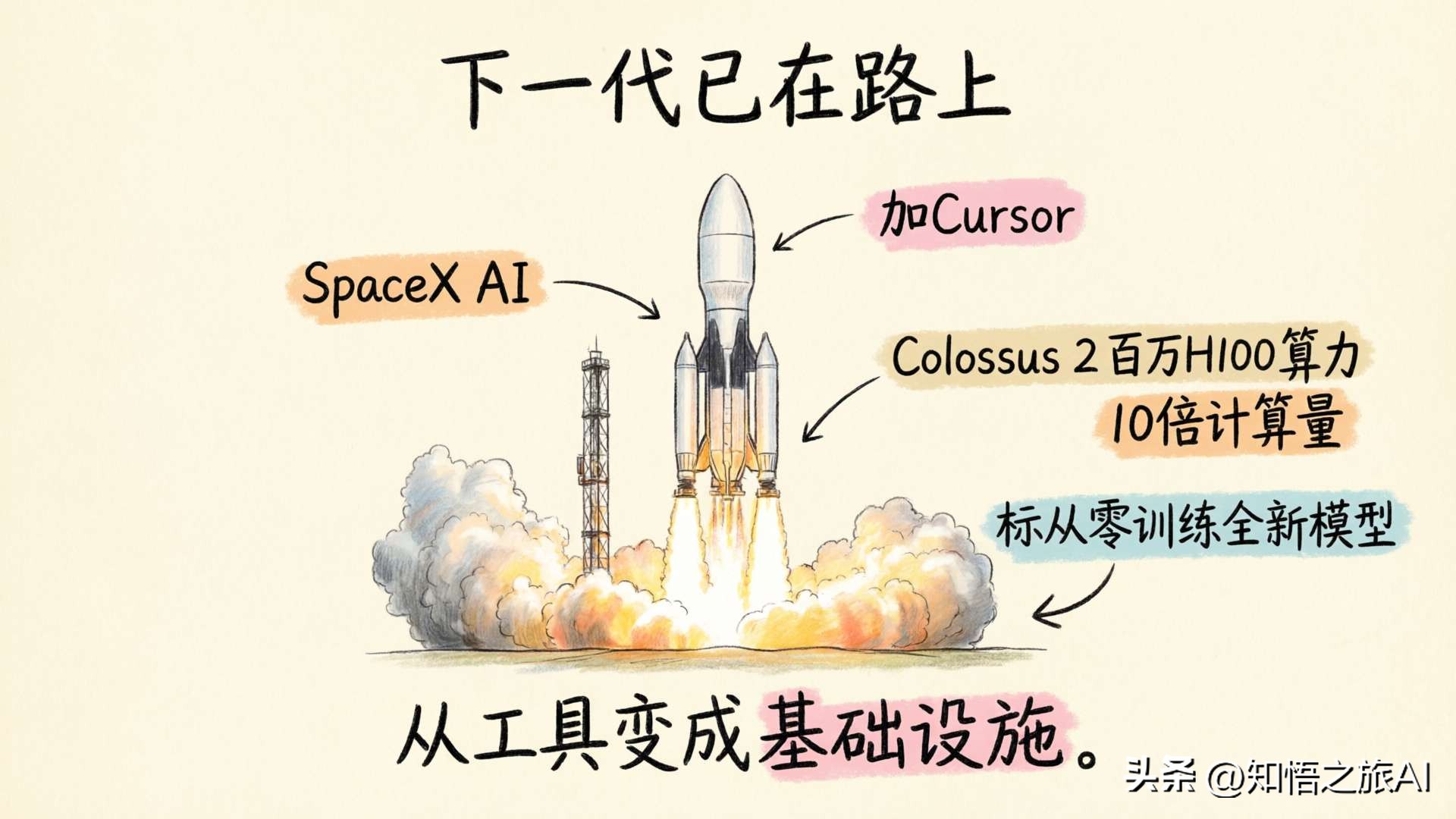
They are collaborating with SpaceXAI to train an entirely new, much larger model from scratch using Colossus 2’s million H100 equivalent computing power, with a total computational volume 10 times that of Composer 2.
This is not fine-tuning. It’s training from the ground up.
Cursor is positioning itself from “the best AI programming tool” to “the infrastructure for AI programming.” If they can master the foundational model themselves, it won’t just be a tool-level differentiation but an absolute barrier at the model level.
An Old Programmer’s Judgment
After using Composer 2.5 for two days, my biggest feeling isn’t that “it’s smarter,” but rather “I finally dare to hand long tasks over to it.”
Previously, when using AI to write code, my workflow was “I plan, AI executes fragments.” If a task exceeds 10 steps, I’d rather write it myself because monitoring the AI to fix its fragmented errors is more tiring than writing it myself.
Composer 2.5 gave me the confidence to hand over an entire module for the first time. It doesn’t mean it won’t make mistakes—it still will. But the way it makes mistakes has changed: previously, it was a system crash where it “forgot what it was doing halfway through,” now it’s a local issue where “a specific step needs correction.”
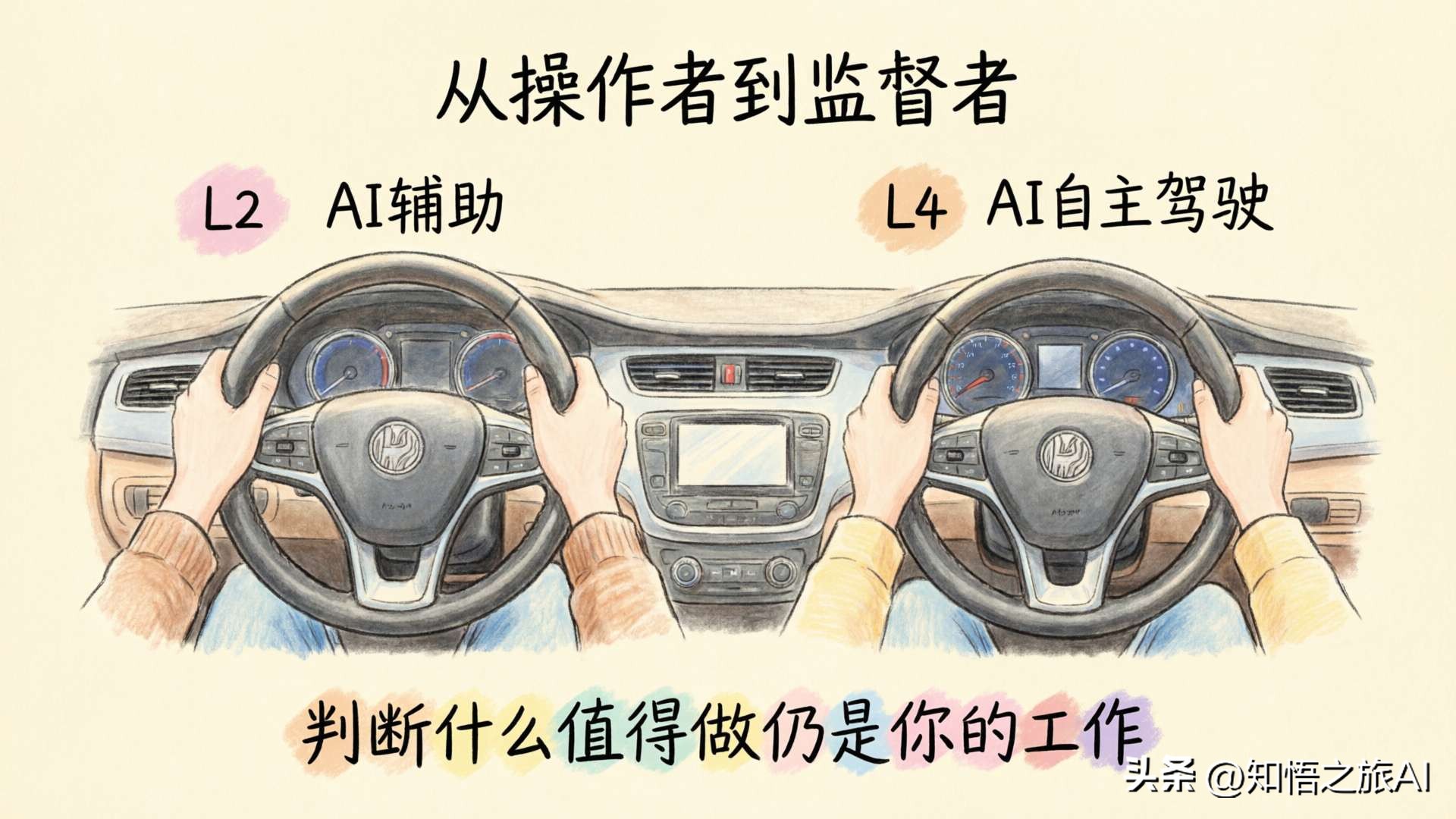
This is like the leap from L2 to L4 in autonomous driving: it doesn’t mean you no longer need humans; rather, the human role shifts from “operator” to “supervisor.”
For those of us who have been coding for over a decade, this feeling is subtle—you’re witnessing a skill you rely on being caught up by a model at a visibly rapid pace.
But it’s not “programming” itself that it’s catching up on. It’s catching up on “execution.” And determining what’s worth doing is still your job.
Cursor Composer 2.5 is now available in Cursor. Standard mode is $2.50/M input, fast mode (default) is $15.00/M. First week has double usage. Trained based on Kimi K2.5 open-source checkpoints, the next-generation model is being trained from scratch in collaboration with SpaceXAI.
If you found this insightful, please like, share, and support; to not miss updates, remember to star⭐. See you next time.
Search for the public account: “Journey of Knowledge” to follow me for more.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.